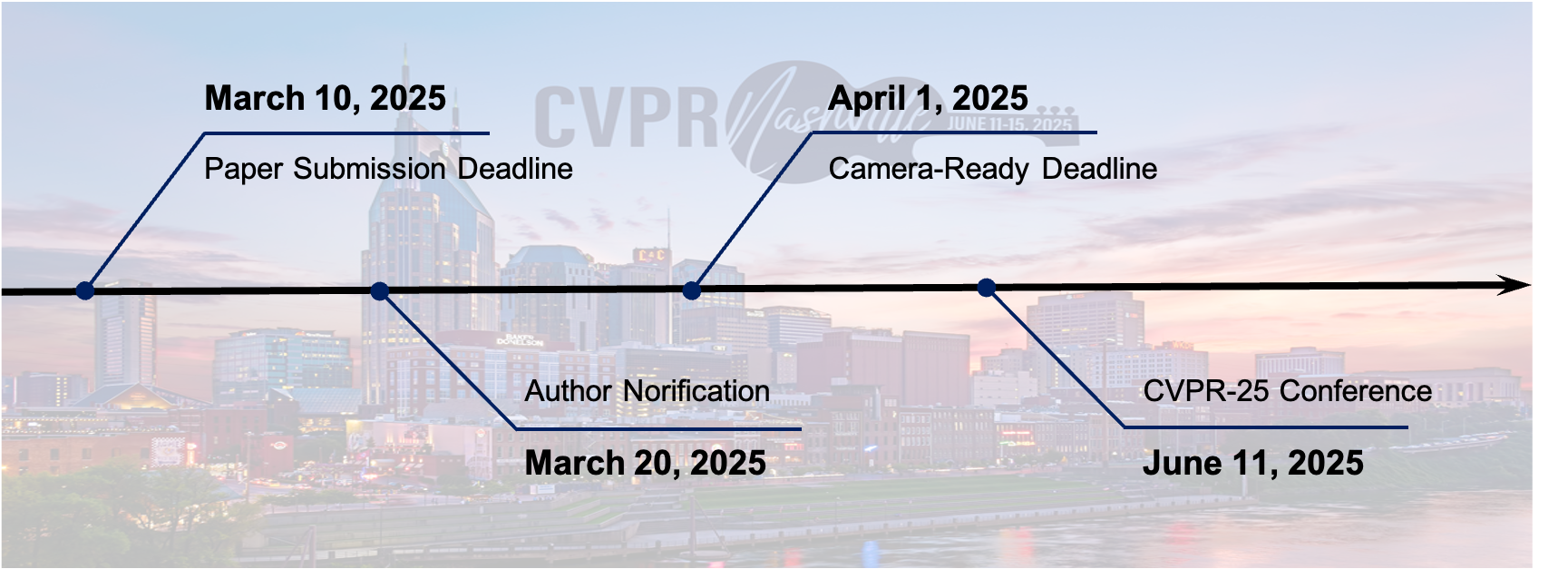
Important Dates
Foundation models (FMs) have demonstrated powerful generative capabilities, revolutionizing a wide range of applications in various domains including computer vision. Building upon this success, X-domain-specific foundation models (XFMs, e.g., Autonomous Driving FMs, Medical FMs) further enhance performance in specialized tasks within their respective fields by training on a curated dataset that emphasizes domain-specific knowledge and making architectural modifications specific to the task. Alongside their potential benefits, the increasing reliance on XFMs has also exposed their vulnerabilities to adversarial attacks. These malicious attacks involve applying imperceptible perturbations to input images or prompts, which can cause the models to misclassify the objects or generate adversary-intended outputs. Such vulnerabilities pose significant risks in safety-critical applications in computer vision, such as autonomous vehicles and medical diagnosis, where incorrect predictions can have dire consequences. By studying and addressing the robustness challenges associated with XFMs, we could enable practitioners to construct robust, reliable XFMs across various domains.
The workshop will bring together researchers and practitioners from the computer vision and machine learning communities to explore the latest advances and challenges in adversarial machine learning, with a focus on the robustness of XFMs. The program will consist of invited talks by leading experts in the field, as well as contributed talks and poster sessions featuring the latest research. In addition, the workshop will also organize a challenge on adversarial attacking foundation models.
We believe this workshop will provide a unique opportunity for researchers and practitioners to exchange ideas, share latest developments, and collaborate on addressing the challenges associated with the robustness and security of foundation models. We expect that the workshop will generate insights and discussions that will help advance the field of adversarial machine learning and contribute to the development of more secure and robust foundation models for computer vision applications.
| Workshop Schedule | |||
| Event | Start time | End time | |
| Opening Remarks | 8:30 | 8:40 | |
| Invited Talk #1: Prof. Vishal M Patel | 8:40 | 9:00 | |
| Invited Talk #2: Prof. Chaowei Xiao | 9:00 | 9:20 | |
| Invited Talk #3: Prof. Florian Tramèr | 9:20 | 9:40 | |
| Invited Talk #4: Prof. Alfred Chen | 9:40 | 10:00 | |
| Distinguished Paper Award | 10:00 | 10:10 | |
| Invited Talk #5: Prof. Bo Han | 10:10 | 10:30 | |
| Invited Talk #6: Prof. Jing Shao | 10:30 | 10:50 | |
| Challenge Session | 10:50 | 11:05 | |
| Poster Session | 11:00 | 12:00 | |
| Lunch (12:00-13:00) | |||

|
Vishal
|
|
Johns Hopkins University |

|
Chaowei
|
|
University of Wisconsin, Madison |
 |
Florian
|
|
ETH Zürich |
 |
Alfred
|
|
University of California, Irvine |
 |
Bo
|
|
Hong Kong Baptist University |

|
Jing
|
|
Shanghai AI Laboratory |

|
Tianyuan
|
|
Beihang |

|
Siyang
|
|
Zhongguancun |

|
Aishan
|
|
Beihang |

|
Jiakai
|
|
Zhongguancun |

|
Siyuan
|
|
National University |
 |
Felix
|
|
GenAI at Meta |

|
Qing
|
|
A*STAR |

|
Xinyun
|
|
Google Brain |

|
Yew-Soon
|
|
Nanyang Technological |

|
Xianglong
|
|
Beihang |
 |
Dawn
|
|
UC Berkeley |
 |
Alan
|
|
Johns Hopkins |
 |
Philip
|
|
Oxford |

|
Dacheng
|
|
Nanyang Technological |
Timeline
| Challenge Timeline | |
| Mar 24, 2025 | Competition starts |
| Mar 26, 2025 | Phase 1 starts |
| April 16, 2025 | Phase 1 ends |
| April 21, 2025 | Phase 2 starts |
| May 11, 2025 | Phase 2 ends |
| May 30, 2025 | Results will be released and participants will be selected to present |
| June 2025 | Awards and presentation |
Challenge Chair
|
|
Siyang
|
|
Zhongguancun |
 |
Zonglei
|
|
Beihang |
 |
Zonghao
|
|
Beihang |
 |
Hainan
|
|
Data Space |
 |
Zhilei
|
|
Data Space |
 |
Haotong
|
|
ETH |
 |
Yue
|
|
Pengcheng |
 |
Lei
|
|
Tsinghua |
|
|
Xianglong
|
|
Beihang |




